What Ritivel users actually want
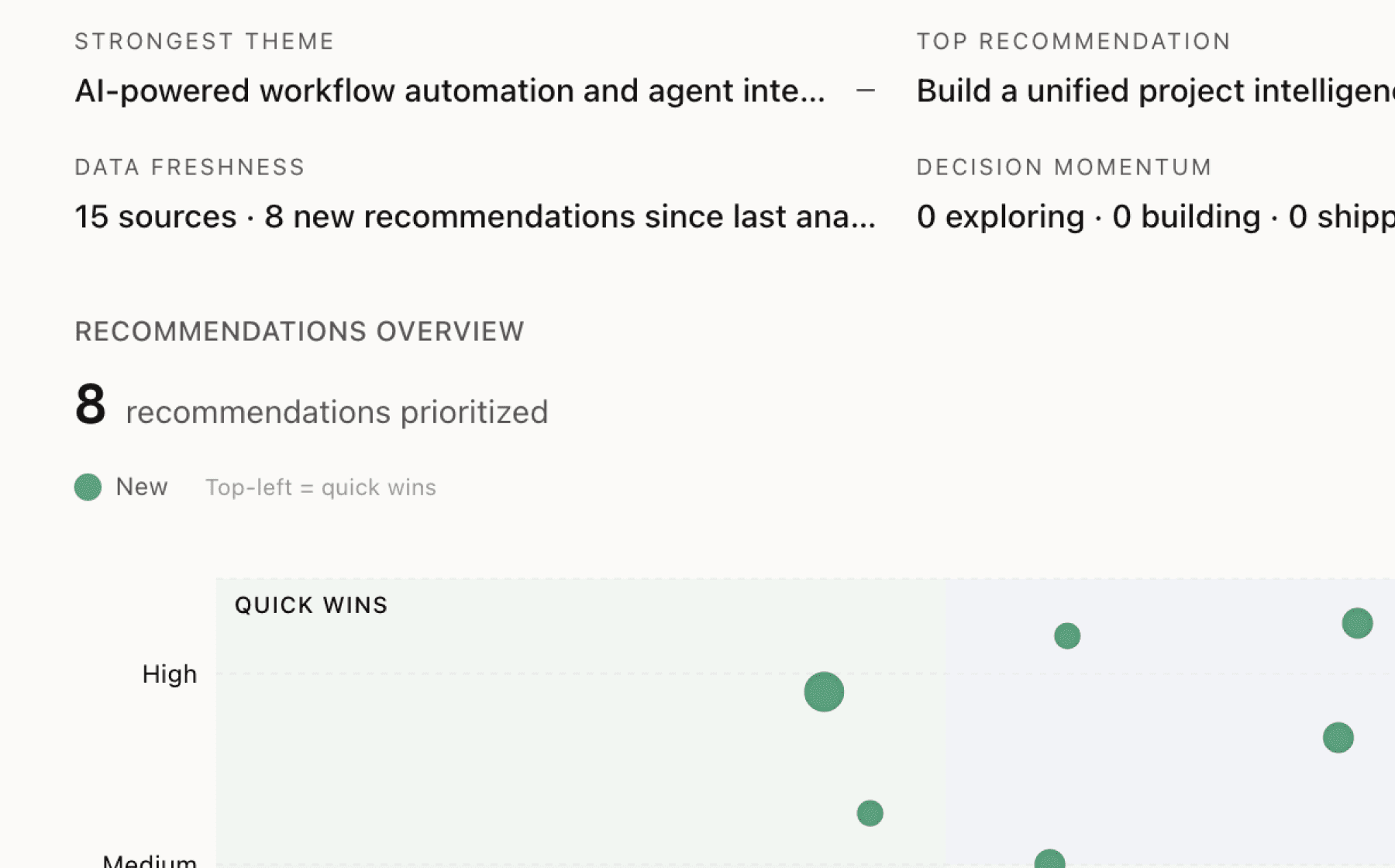
Mimir analyzed 1 public source — app reviews, Reddit threads, forum posts — and surfaced 9 patterns with 6 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build enterprise-grade on-premise deployment with air-gapped mode and zero data retention guarantees
High impact · Large effort
Rationale
Data sovereignty is the gatekeeper to enterprise adoption. Three independent sources confirm that regulatory teams cannot use cloud solutions due to IT, legal, and data-privacy restrictions on sensitive IP. This is not a feature request—it is a binary adoption criterion. Without local deployment and zero data retention, you cannot sell to pharma, biotech, or medtech companies operating under strict compliance regimes.
The product already provides 100% local deployment, but this recommendation emphasizes making this capability enterprise-ready with clear documentation, audit trails, and contractual guarantees. This includes air-gapped operation for the most sensitive environments, explicit zero data retention policies that legal teams can review, and deployment tooling that IT teams can validate. This is the foundation that enables all other features to deliver value.
Prioritizing this ensures you can expand within existing accounts and win competitive deals where compliance is the first filter. It also differentiates you from AI vendors that cannot credibly serve regulated industries.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
5 additional recommendations generated from the same analysis
Traceability is not optional in regulatory submissions. Two sources confirm that QA, auditors, and regulators require defensible sourcing for every statement. Without this, your AI-generated drafts become liabilities rather than assets—users cannot submit documents they cannot defend. This creates friction that undermines the core value proposition of speed.
CSR automation represents the highest-value use case based on explicit customer demand. Evidence shows teams want protocol and SAP inputs to generate complete CSRs in minutes with traceability. This is a high-volume, high-pain workflow that currently takes weeks of manual effort. Clinical study reports are submission-critical documents where time savings directly translate to faster market access and revenue realization for your customers.
Regulatory reviewers expect perfect consistency across submissions, and manual consistency checking is error-prone and time-consuming. This creates a hidden productivity drain and introduces submission risk. When different modules contradict each other or when updates to one section are not reflected in cross-references, regulators flag inconsistencies that trigger additional review cycles.
CTD automation is explicitly requested as a priority workflow, covering literature search via PubMed, Module 2 summary drafting with cross-references, and Module 5 literature automation. This represents another high-volume documentation workflow where teams currently spend significant manual effort synthesizing literature and maintaining cross-references across modules.
The platform serves four distinct customer segments with potentially different workflows and pain points. CROs operate under different constraints than internal pharma teams—they handle multiple clients, need to demonstrate efficiency to win contracts, and may have different compliance requirements. Biotech and medtech companies may prioritize different submission types or have smaller regulatory teams that need more end-to-end automation.
Insights
Themes and patterns synthesized from customer feedback
The platform supports comprehensive automation across CSRs, INDs, NDAs, BLAs, nonclinical reports, briefing documents, and more, enabling a single solution for multiple submission types. This breadth reduces vendor fragmentation and increases stickiness.
“Product supports comprehensive regulatory workflow automation across CSRs, INDs, NDAs, BLAs, nonclinical reports, briefing documents, and more”
Instant access to FDA and ICH guidelines without signup friction lowers the barrier to product trial and helps teams quickly resolve regulatory questions. This is a secondary feature that supports primary workflows.
“Regulatory Search - Instant answers from FDA and ICH guidelines without signup required”
CSR automation (Protocol + SAP input → complete CSR in minutes) and CTD automation (literature search, Module 2 summaries, cross-references, Module 5 literature) are explicit high-priority feature requests, indicating these document types are volume drivers and pain points.
“Automate Clinical Study Reports (CSRs) - Protocol + SAP input to complete CSR output in minutes with word-level traceability”
Regulatory reviewers expect perfect consistency across all drafts, updates, and submissions to prevent surprises and additional review cycles. Manual consistency checking across complex, multi-module documents is error-prone and time-consuming.
“Regulatory reviewers expect consistency across drafts, updates, and submissions to avoid surprises and review cycles”
The platform serves four distinct user segments—pharma companies, biotech companies, medtech companies, and CROs/CDMOs—each with potentially different regulatory workflows, pain points, and go-to-market strategies. This segmentation is foundational for targeting growth.
“Platform serves four key user segments: Pharma companies, Biotech companies, Medtech companies, and CROs/CDMOs”
Regulatory teams operate under strict IT, legal, and data-privacy requirements that prevent cloud storage and third-party access to sensitive intellectual property. Local-only deployment with zero data retention is table stakes for enterprise adoption.
“Regulatory teams must meet strict IT, legal, and data-privacy requirements that restrict cloud storage and third-party access”
Regulatory teams currently spend months on manual documentation work that could be automated, freeing them to focus on higher-value scientific activities. This represents a core productivity gain that directly impacts both speed-to-submission and team morale.
“Regulatory teams spend months on documentation that could be automated, time better spent on science”
Regulators, auditors, and QA teams require word-level traceability showing exactly where every statement and claim originates from source documents. Submissions without clear, defensible sourcing create friction and risk additional review cycles.
“QA, auditors, and regulators require defensible traceability of where every statement and claim originates from source documents”
Domain-specific terminology and regulatory language complexity regularly lead to factual errors in critical documents like CTDs and CSRs. These errors can trigger additional review cycles or submission rejections, making accuracy automation a direct revenue driver.
“Domain-specific terminology and regulatory language complexity leads to factual errors in high-stakes documents like CTDs and CSRs”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.