What Rastro users actually want
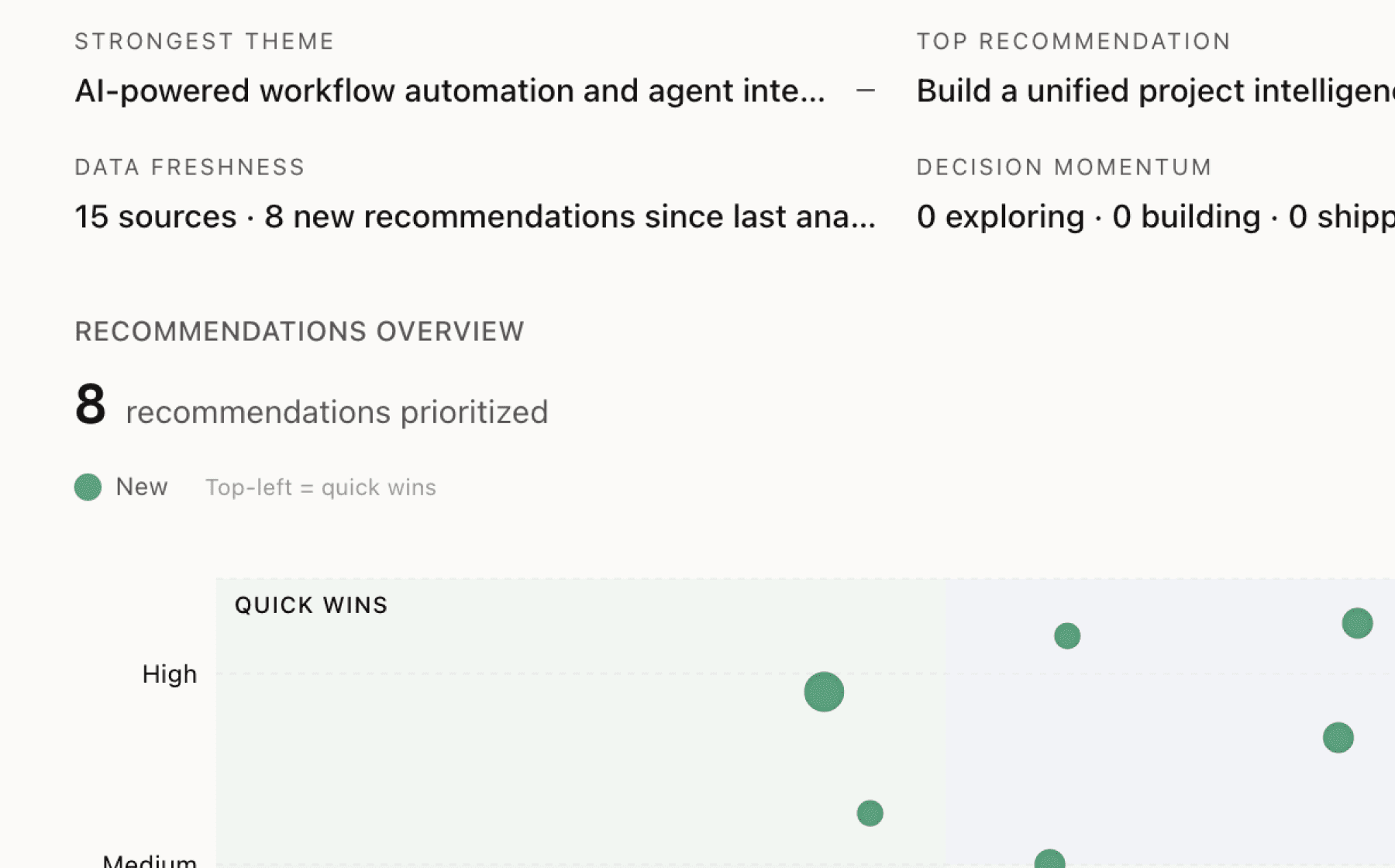
Mimir analyzed 4 public sources — app reviews, Reddit threads, forum posts — and surfaced 11 patterns with 7 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build automated supplier onboarding pipeline with sub-24-hour turnaround guarantee
High impact · Medium effort
Rationale
Supplier onboarding currently takes 6-8 weeks of manual effort extracting specs from PDFs, manuals, and websites with no predictable endpoint. This unpredictability makes it impossible to commit to launch dates or scale operations reliably. Four sources identify this as a critical bottleneck preventing business growth.
The evidence shows a clear transformation path: one user reports Rastro converted their 6-8 week manual process into an under-24-hour automated operation. Another states that before automation, onboarding a supplier like Hella would have been a slow, painful process. The platform already demonstrates internet-scale data crawling to extract comprehensive product specs from verified sources.
This addresses the most significant operational constraint in the business. Predictable onboarding directly enables teams to commit to launch timelines, scale supplier relationships, and expand addressable market. The capability foundation exists — packaging it as a guaranteed turnaround product differentiator would remove the primary barrier to business scaling.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
6 additional recommendations generated from the same analysis
Product information currently lives in fragmented spreadsheets with different formats for each marketplace. Every modification breaks another cell and data is never truly clean. Different marketplaces require conflicting character limits, SEO approaches, and tone guidelines, forcing manual reformatting for each channel. This fragmentation creates cascading errors that break downstream processes.
Catalogs often contain thousands of SKUs where critical attributes are missing or incomplete. Four sources identify this as blocking market launch and competitive pricing decisions. Without complete attribute data and market benchmarks, teams either delay launch or guess on pricing, risking both margins and competitiveness.
Teams face an impossible tradeoff: maintain strict data quality standards across tens of thousands of annual product decisions, or sacrifice accuracy for speed. Manual workflows ensure accuracy but create capacity bottlenecks that limit innovation pace. One user manages tens of thousands of product decisions annually requiring extensive manual effort for each SKU.
Users report saving 80+ hours per week on manual catalog operations and transforming production timelines for 10,000 SKU catalogs. However, the value isn't just time saved — it's enabling work that was previously impossible. One user states their partnership with Rastro is the difference between projects never leaving backlog versus becoming achievable within committed timelines.
The platform achieves auto-configuration in approximately 5 minutes after schema definition and provides full REST API access. One implementation aligned schema with Shopify metafields via API integration. This rapid setup reduces implementation friction and shortens time-to-value.
Each enriched data field links to its source, enabling audit and verification. This supports compliance requirements and builds confidence in data quality. Intelligent routing ensures low-confidence extractions go to review queues while high-confidence data auto-accepts.
Insights
Themes and patterns synthesized from customer feedback
Each enriched data field is linked to its source, providing traceability for audit purposes and enabling QA teams to verify accuracy against source documents. This sourcing transparency supports compliance requirements and builds confidence in data quality. Intelligent routing (low-confidence extractions to review queues, high-confidence data auto-accepts) optimizes review workload while maintaining quality standards.
“Each captured data field is source-linked for traceability and audit purposes”
Rastro achieves auto-configuration in approximately 5 minutes after schema definition and provides a full REST API for programmatic access to enrichment and catalog management. This enables fast setup and integration with existing systems, reducing implementation friction. API-based integration supports advanced workflows like schema alignment with platforms (e.g., Shopify metafields) and custom automation.
“Auto-configuration takes approximately 5 minutes after defining catalog schema”
Rastro supports translation and localization across 50+ languages while preserving brand voice consistency across markets. This reduces the manual effort required for multilingual catalog management and ensures consistent brand messaging globally. Support for multiple languages is critical for teams serving international markets or export-heavy customer bases.
“Multi-language catalog support with translation and localization for 50+ languages while preserving brand voice”
Automation transforms workload from weeks to hours, enabling teams to redirect effort from manual data operations toward creative work, quality assurance, and strategic initiatives. Users report substantial improvements in production speed, throughput, and error rates across 10,000+ SKU catalogs. This efficiency gain directly expands addressable market capacity and improves team productivity.
“Rastro didn't just save us time. Rastro gave us a new scale.”
Product teams must maintain strict data quality standards (spec precision, attribute accuracy, brand voice consistency) while managing tens of thousands of annual product decisions, creating a capacity bottleneck that slows innovation. Manual workflows ensure accuracy but limit pace, forcing difficult tradeoffs between quality and speed. AI-powered extraction with intelligent validation and traceability enables both high data quality and fast throughput.
“Manual catalog operations workflows can limit pace of innovation despite ensuring accuracy and consistency”
Rastro enriches catalogs by extracting product data from manufacturer sites, supplier documentation, and live market pricing across geographies. The platform fills content gaps, standardizes data against catalog schema, and validates it against quality thresholds. This multi-source enrichment approach enables teams to achieve high attribute coverage (98%+) in days rather than months.
“Rastro enables catalog enrichment by filling content gaps from manufacturer sites and supplier documentation”
Different marketplaces have conflicting requirements (character limits, SEO keywords, tone/voice) that currently require manual reformatting of product content for each channel. Automated channel-adapted content generation respects these constraints while maintaining brand voice and data consistency. This eliminates repetitive reformatting work and reduces risk of publishing content that violates marketplace requirements.
“Different marketplace constraints (character limits, SEO, tone) require manual reformatting for each channel”
Product catalogs often have thousands of SKUs with complex taxonomies where critical attributes are missing or incomplete, delaying launch and reducing ability to price competitively. Without attribute completeness and market pricing data, teams either delay launch or guess on pricing, risking both competitiveness and margins. Rapid, high-quality attribute enrichment from multiple sources provides the data foundation needed for confident market entry.
“Thousands of SKUs with complex taxonomy and half missing attributes in product catalogs”
Manual supplier onboarding takes 6-8 weeks due to the need to manually extract specs from PDFs, manuals, and websites with no clear endpoint, making it impossible to commit to launch dates or scale operations reliably. Sparse or low-fidelity supplier data (missing specs, compatibility details, descriptions) creates a structural bottleneck. Automating data extraction and validation converts this to a predictable, sub-24-hour operation.
“Rastro's approach transforms 6-8 week manual project into under 24-hour automated operation”
Product information stored in unstructured spreadsheets with different formats for each marketplace (character limits, SEO, tone) forces manual reformatting and creates cascading errors when updates are made. Data inconsistency cascades through systems, breaking downstream processes and requiring extensive correction cycles. Centralized, channel-aware logic eliminates version conflicts and ensures consistent, reliable data.
“The problem wasn't translation, it was chaos. Every modification broke another cell—our data was never really clean.”
Users spend hundreds of manual hours per week on repetitive catalog tasks like data entry, copying, pasting, and corrections across spreadsheets and marketplaces. This manual work blocks innovation cycles, creates backlogs that never clear, and prevents teams from committing to reliable launch timelines. Eliminating this friction directly enables business growth and unlocks higher-value work.
“Hundreds of manual hours spent copying, pasting, and correcting multilingual product data”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.