What Dedalus Labs users actually want
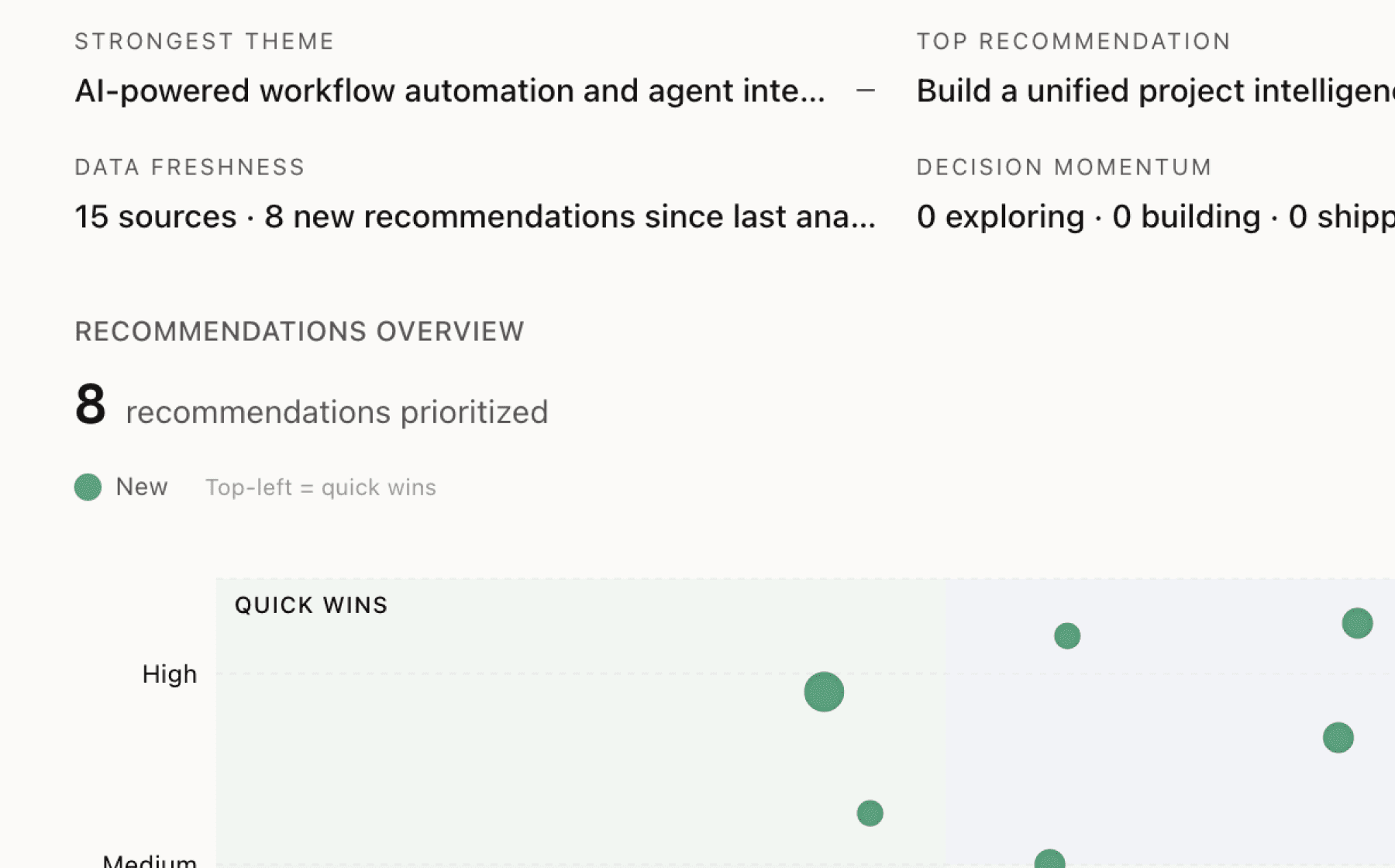
Mimir analyzed 7 public sources — app reviews, Reddit threads, forum posts — and surfaced 10 patterns with 7 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Implement marketplace quality standards with automated performance testing and certification tiers
High impact · Large effort
Rationale
The data reveals critical reliability gaps that undermine marketplace trust. The get_server_capabilities tool shows a 15.8% success rate despite being the most-called function with 38 invocations, while list_sessions fails 60% of the time. Response times vary wildly from 1.1s to 6.2s across featured tools, and fragmentation is visible in duplicate implementations like two Gmail variants and two Brave search servers with dramatically different usage patterns.
These inconsistencies create a paradox where the marketplace's breadth (25+ servers spanning search, code, email, databases, and automation) becomes a liability rather than an asset. Users cannot reliably evaluate tool quality before integration, forcing them to discover failures in production. For a platform targeting product managers and engineering leads making production deployment decisions, this creates unacceptable risk.
A certification system with automated testing, minimum performance thresholds (success rate, latency, uptime), and visible quality badges would transform marketplace browsing from guesswork into informed decision-making. This directly supports retention by ensuring users' first integrations succeed, while the 80% revenue share model ensures creators are incentivized to meet quality bars. Combined with the existing DAuth security framework, quality certification becomes the second pillar of production-readiness.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
6 additional recommendations generated from the same analysis
The marketplace shows early traction with healthy network effects but lacks maturation infrastructure. Context7 dominates with 1.3K calls while most tools languish under 200, and duplicate implementations (two Gmail servers with 21 vs 24 tools, two Brave variants with 13 vs 3 calls) fragment user attention without adding value. The 80% revenue share creates strong creator incentives, but adoption is concentrated among a handful of tools rather than distributed across the ecosystem.
Python 3.10+ requirements, package manager recommendations (uv), and DAuth credential binding create unnecessary friction between discovery and deployment. While the 5-line SDK promises fast time-to-value, users still hit setup barriers when activating marketplace tools. For target users (product managers, founders, engineering leads), requiring Python environment configuration or understanding package managers contradicts the promise of building agents in minutes.
Users can test Exa server directly in marketplace via AI agent chat, and Command Palette enables quick MCP discovery, but evaluation remains shallow. Users cannot compare competing tools (two Gmail servers, two Brave implementations) without manual integration and testing. For engineering leads making production deployment decisions, this creates unnecessary friction between discovery and confident selection.
DAuth represents a critical competitive advantage. It addresses the biggest barrier to production AI deployment through zero-trust architecture, client-side encryption, and hardware-secured credential handling in The Enclave. The framework enables users to trust MCPs from any creator the same way they would trust Google's implementations. Yet this differentiator is invisible during marketplace browsing, where users see tool descriptions but not security posture.
Multi-provider support (OpenAI, Anthropic, Google, DeepSeek, Mistral, xAI) and model-agnostic tooling create flexibility, but users lack guidance on cost optimization. The Pro tier's optimized inference speed and BYOK capabilities suggest cost matters, and pay-as-you-go pricing ($0.0025-0.0050 per tool call) makes cost visibility important for retention. Users building complex agent architectures with up to 50 MCP servers face non-trivial infrastructure costs without tools to optimize spending.
The platform provides robust infrastructure (5-line SDK, one-click deployment, 25+ marketplace tools, multi-model support) but requires users to architect agents from scratch. Pre-built tools like Slack, Notion, GitHub, and Linear suggest common productivity workflows, yet users must still design agent logic, craft prompts, and integrate tools manually. For product managers and founders without deep technical expertise, this gap between infrastructure and working solution creates friction.
Insights
Themes and patterns synthesized from customer feedback
Command Palette enables quick MCP discovery while in-marketplace testing via AI agents reduces friction for evaluating tools before deployment. Streamlined exploration and validation improve engagement by lowering the cost of experimentation.
“Marketplace includes Command Palette for searching and running commands, enabling quick discovery of MCP servers”
Real-time dashboards provide usage metrics, cost breakdown, and detailed tool performance analytics enabling users to monitor production deployments. Visibility into success rates and response times supports informed decision-making on tool selection and optimization.
“Real-time monitoring dashboard tracks balance, request counts, and usage cost breakdown”
Some MCP server dependencies (Python 3.10+, specific package managers) may limit accessibility for non-technical users building agents. Simplifying technical requirements could expand addressable audience among product and business-focused users.
“MCP server requires Python 3.10+ and recommends uv for package management, setting technical requirements for users”
Y Combinator backing provides institutional credibility and resources that support user confidence in platform stability and long-term viability.
“Y Combinator backing signals credibility and institutional support for the platform”
25+ diverse tool integrations with 80% revenue share create self-sustaining incentives for creators while expanding available tools for users. Varying adoption metrics (Context7 at 1.3K calls, others under 200) and community duplication patterns indicate healthy ecosystem expansion alongside maturation challenges.
“Marketplace monetization: earn 80% revenue when others use published MCP servers (coming soon)”
Performance varies significantly across marketplace (1.1s to 6.2s response times, 15.8% success rate on critical operations), with fragmentation in tool variants and setup friction creating user friction. Addressing reliability and standardizing quality thresholds is essential for maintaining user trust and marketplace value.
“Brave search has 2 variants (tsion and windsor) in marketplace with different usage (13 calls vs 3 calls), indicating fragmentation”
Tiered freemium model (50 free calls/month, $20/month Pro tier) with transparent pay-as-you-go costs ($0.0025-0.0050 per call) and anytime plan changes reduce friction for individual creators while supporting enterprise scaling. Pricing structure directly supports retention by matching user growth patterns.
“Pay-as-you-go pricing: $0.0050 per tool call for Hobby, $0.0025 for Pro after free monthly allocation”
5-line SDK with multi-language support (Python, TypeScript) and one-click cloud deployment dramatically reduce friction to building and deploying agents. Fast time-to-value directly drives engagement by removing setup barriers and enabling rapid iteration.
“SDK reduces agent creation to 5 lines of code, enabling fast time-to-value”
Support for diverse LLM providers (OpenAI, Anthropic, Google, DeepSeek, Mistral, xAI) with universal model access and model-agnostic tooling enables users to optimize for cost, performance, and capability within a single platform. This flexibility reduces switching friction and supports sophisticated agent architectures.
“Support for multiple LLM providers: OpenAI, Anthropic Claude, Google Gemini, DeepSeek, Mistral, xAI with universal model access”
Zero-trust architecture, client-side encryption, and hardware-secured credential handling remove critical barriers to production deployment. DAuth framework and secure key management directly address developer concerns about malicious MCP servers and vulnerability exposure, becoming essential infrastructure for enterprise adoption.
“Launched most secure MCP Auth framework, addressing authentication security as a key differentiator”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.