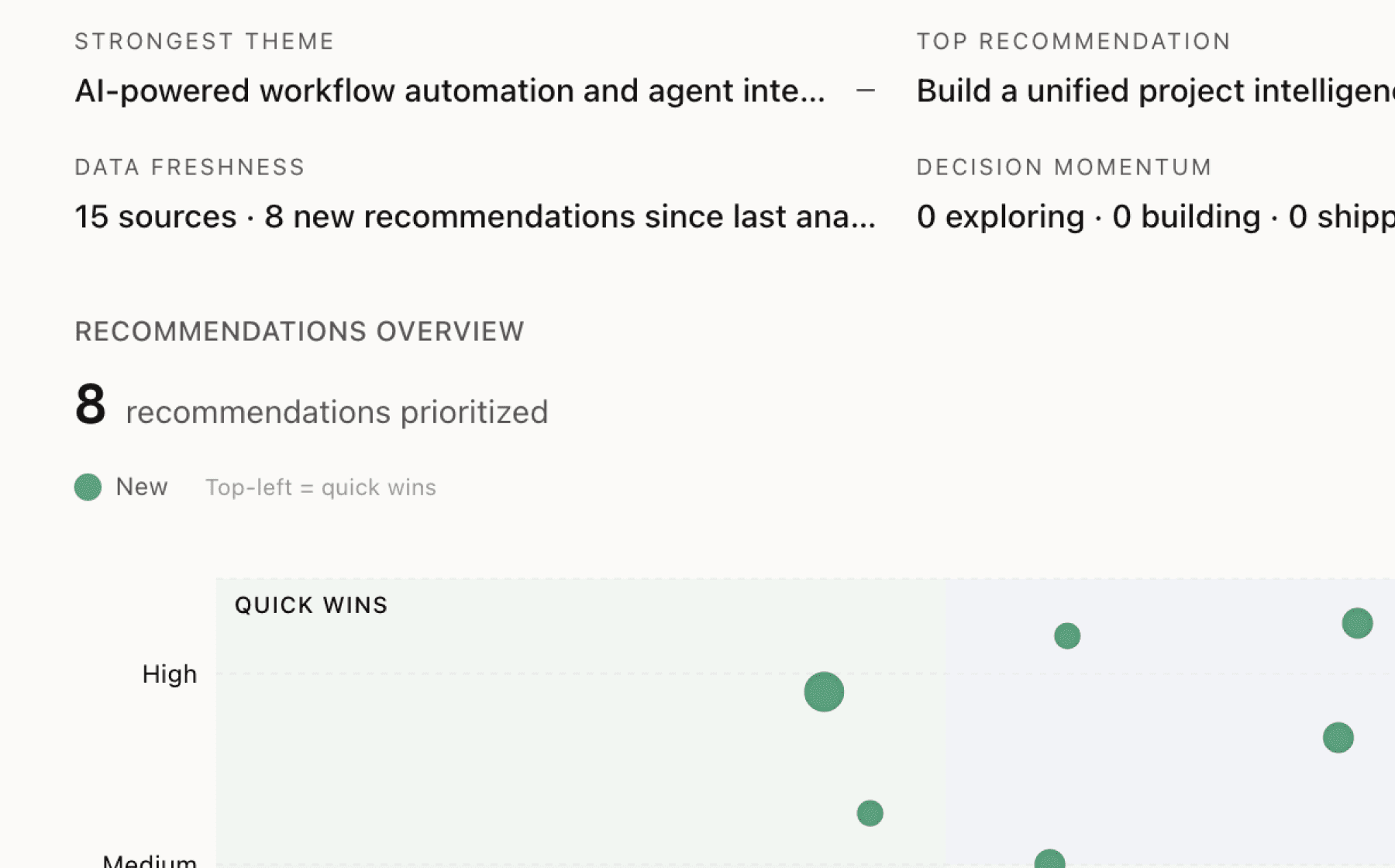
What Adaptional users actually want
Mimir analyzed 3 public sources — app reviews, Reddit threads, forum posts — and surfaced 11 patterns with 6 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build a transparent edge case handling system that shows users which extraction scenarios are confidence-graded
High impact · Medium effort
Rationale
The final 10-20% of extraction development creates exponential complexity, particularly for property data where multiple properties share addresses and field comparison thresholds remain ambiguous. Rather than pursuing perfect extraction accuracy, expose confidence levels to users and let them handle low-confidence extractions manually. This directly addresses the credibility gap in insurance tech by being honest about automation limits while still delivering the core value proposition.
Insurance buyers are already skeptical of automation promises because the industry has historically overpromised. By surfacing confidence scores and flagging edge cases transparently, you turn a technical constraint into a trust-building feature. Users retain control over ambiguous decisions while benefiting from time savings on the 80-90% of extractions that work reliably.
This recommendation also supports the citation feature already in place. If citations allow underwriters to verify source data, confidence grading becomes the natural next step — showing not just where data came from but how certain the system is about its interpretation. The combination positions the product as a decision support tool rather than a black box, which aligns with how underwriters actually want to work.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
5 additional recommendations generated from the same analysis
Property extraction faces a specific technical challenge that compounds the edge case problem: deciding when properties with different values at the same address represent the same entity versus distinct properties. Field comparison thresholds are inherently domain-specific and vary by carrier, line of business, and even underwriter preference.
LLMs require significant production engineering to process insurance documents effectively, and the first 80-90% of development happens quickly while the final stages become exponentially harder. This creates a predictable implementation risk: customers will see impressive demos but struggle when deploying against their actual document corpus.
The insurance technology sector has created skepticism by overpromising automation capabilities, and your product faces the same credibility challenge even though the underlying technology has improved. The current positioning emphasizes automation reducing processing time from hours to minutes, which risks repeating the industry's historical mistake of overselling.
The current terms provide service as-is with no warranties and liability capped at 12 months of fees. For early adopters and smaller customers, this may be acceptable. For enterprise insurance carriers with strict compliance requirements and risk management standards, these terms create a procurement barrier regardless of technical capabilities.
The 60-day export window after termination and 30-day notice requirement create switching friction that may boost short-term retention but damage long-term trust. Insurance carriers operate in a heavily regulated industry where data portability and vendor lock-in are sensitive topics, particularly for a new entrant trying to overcome the credibility gap.
Insights
Themes and patterns synthesized from customer feedback
The service commits to 99.5% uptime availability, but excludes scheduled maintenance and circumstances beyond reasonable control. Technical support is provided during business hours only, with priority support available under separate agreement.
“Service level commitment: 99.5% uptime target, excluding scheduled maintenance and circumstances beyond reasonable control”
The product must comply with state insurance codes, HIPAA (where applicable), and relevant privacy laws. Customer data is retained by the user with the vendor having only a limited license for service provision and model improvement, reflecting regulatory constraints on data handling.
“Compliance required with insurance industry regulations including state insurance codes, HIPAA (where applicable), and relevant privacy laws”
After service termination, customers have a 60-day window to export data, and either party must provide 30 days' notice to terminate the contract. This relatively short migration window may create switching friction and retention challenges.
“60-day data export window provided after service termination; 30-day notice required for contract termination by either party”
The system includes citations for all work outputs, allowing underwriters to instantly verify source data and trace extraction decisions back to original documents. This transparency feature supports user confidence and auditability.
“AI provides citations for all work outputs, enabling underwriters to instantly review source data”
The system automatically extracts structured data from unstructured insurance documents and emails, then analyzes risk by applying underwriting guidelines. It also syncs with internet, third-party, and carrier data to verify application data and identify missed exposures, reducing manual data entry from hours to minutes.
“AI extracts data from emails and documents, then analyzes risk based on underwriting guidelines”
The product is provided as-is with all warranties disclaimed (including merchantability and fitness for purpose), and liability is capped at 12 months of fees paid with no coverage for indirect or consequential damages. This is a contractual risk constraint that may impact adoption among enterprise customers with strict compliance or SLA requirements.
“No warranty guarantees; services provided 'as is' with all warranties disclaimed including merchantability and fitness for purpose”
The insurance technology sector has historically overpromised and underdelivered on automation capabilities, creating skepticism among buyers. This trust deficit is directly relevant to user adoption and retention of new AI underwriting tools, as customers approach claims of automation benefits cautiously.
“Insurance technology has historically overpromised and underdelivered on automation capabilities”
By automating data extraction and entry, the system shifts underwriter time from clerical tasks to higher-value decision-making and risk analysis. This reallocation of human effort is positioned as a core value driver for user engagement and productivity.
“AI frees underwriters from data entry tasks to focus on decision-making”
Underwriting submissions in practice come from scattered sources (emails, statements of values, random documents) in inconsistent formats. Systems must reconcile these into unified records with consistent, accurate data—a practical challenge that goes beyond simple extraction.
“Real-world underwriting submissions are messy: emails, statements of values, and random documents must be reconciled into unified records with consistent, accurate data”
While initial extraction system development progresses quickly (first 80-90%), the final 10-20% required to handle edge cases, reconcile conflicts, and manage real-world messiness becomes exponentially harder. This is particularly acute for property-based data where multiple properties at the same address, inconsistent field values, and ambiguous comparison thresholds create compounding challenges.
“the first 80–90% of an extraction system develops relatively quickly. However, the final 10–20%—resolving edge cases, reconciling conflicting information, and handling human error—proves exponentially more challenging”
Flagship models like ChatGPT, Claude, and Gemini cannot process insurance documents effectively without substantial engineering work to become production-grade extraction systems. This engineering gap between research-quality models and deployable systems is a critical implementation barrier for AI underwriting.
“Flagship LLMs like ChatGPT, Claude, and Gemini cannot process insurance documents out of the box; they require significant engineering to become production-grade field extraction systems”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.